

Artificial intelligence has just entered its own "Sputnik moment".
Last week, the large Chinese language model (LLM) startup DeepSeek officially emerged from low-key operations, surprising the US market.
DeepSeek is faster, smarter, and uses fewer resources than other LLMs like ChatGPT. Whether it's content creation or basic queries, its speed far exceeds previous models. More importantly, the model has the ability of "autonomous thinking", so its training cost is said to be lower than previous models.
Sounds great, right? But if you're a tech company betting on the US AI industry, it might not be. The market reacted violently to this development on Monday. Tech stocks plummeted collectively, with market capitalization evaporating over $1 trillion - about half the value of Bitcoin. Nvidia's stock price plunged 17% in a single day, losing $589 billion in market value, setting a record for the largest single-day market value loss in US stock market history. The decline of Nvidia and other tech stocks dragged the Nasdaq Composite Index down 3.1% that day.
And the market selloff was not limited to tech stocks. Energy stocks also suffered heavy losses, with natural gas, nuclear and renewable energy company Vistacorp (with large operations in Texas) plunging about 30%, while Constellation Energy, which is restarting the Three Mile Island nuclear power plant to power Microsoft data centers, also fell more than 20%.
The market's concerns about DeepSeek are simple: The speed of improvement in LLM computing efficiency has far exceeded expectations, the direct consequence of which is a reduction in market demand for GPUs, data centers and energy. Coincidentally, the time when this model became popular is just days after the former president Trump announced a $500 billion "Project Stargate" to accelerate the construction of US AI infrastructure.
Experts have different views on the impact of DeepSeek. On the one hand, some believe this could be a major boon, not a disaster, for the AI industry - just as the improvement in internal combustion engine efficiency did not reduce car demand, but rather drove industry growth.
On the other hand, the data circulating on social media about DeepSeek's training costs may be misleading. Although the new model has indeed reduced costs, it is far less exaggerated than the rumors.
Understanding DeepSeek
DeepSeek was founded in May 2023 by Chinese engineer Liang Wenfeng and received investment from the hedge fund High-Flyer, which Liang also founded in 2016. DeepSeek open-sourced its first model DeepSeek-R1 on January 20 and quickly became a hit on the internet last weekend.
DeepSeek-R1 has several unique features that set it apart from other models, including:
- Semantic understanding: DeepSeek has the ability to "read between the lines". It uses "semantic embeddings" technology to infer the intent and deeper context behind queries, providing more detailed and nuanced responses.
- Cross-modal search: It can parse and cross-analyze different types of media content, meaning it can process text, images, videos, audio and other data simultaneously.
- Self-adaptation: DeepSeek has the ability to continuously learn and self-train - the more data it is fed, the stronger its adaptability. This may allow it to maintain reliability without the need for frequent retraining. In other words, we may no longer need to regularly input new data, as the model can autonomously learn and adjust during operation.
- Massive data processing: DeepSeek is said to be able to process PB-level (Petabyte) data, allowing it to handle huge datasets that other LLMs may struggle with.
- Fewer parameters: DeepSeek-R1 has a total of 67.1 billion parameters, but only requires 37 billion parameters per inference, while the estimated parameter count for each ChatGPT inference is between 500 billion and 1 trillion (OpenAI has not disclosed the exact number). Parameters refer to the inputs and components used to guide and optimize learning during the training process.
In addition to the above features, DeepSeek's most attractive aspect is its self-adjustment and autonomous learning capabilities. This feature not only saves time and resources, but also lays the foundation for the development of autonomous AI agents, enabling their application in areas such as robotics, autonomous driving, and logistics.
Pastel founder and CEO Jeffrey Emmanuel provided an excellent summary of this breakthrough in his article "The Short Case for Nvidia Stock":
"With R1, DeepSeek has essentially conquered an 'AI Holy Grail': enabling a model to develop complex reasoning capabilities through pure reinforcement learning and carefully designed reward functions, without large supervised datasets. Their DeepSeek-R1-Zero experiment demonstrates an astounding achievement: they have successfully trained a model to autonomously develop sophisticated reasoning abilities, self-verify its work, and allocate more compute resources to handle more difficult problems."
The Real Reason DeepSeek Has Wall Street Panicking
DeepSeek is indeed an enhanced version of ChatGPT, but this is not the real reason the financial world was shocked last week - the real reason investors are panicking is the training cost of this model.
The DeepSeek team claims that the training cost of this model is only $5.6 million, but the credibility of this data is questionable.
In terms of GPU hours (the computational cost per hour of each GPU), the DeepSeek team claims they used 2,048 Nvidia H800 GPUs, totaling 2.788 million GPU hours, for pre-training, context expansion, and post-training, at a cost of about $2 per GPU hour.
In comparison, OpenAI CEO Sam Altman stated that the training cost of GPT-4 exceeded $100 million. The training cycle for GPT-4 was 90 to 100 days, using 25,000 Nvidia A100 GPUs, totaling 54 to 60 million GPU hours, at a cost of about $2.50 to $3.50 per GPU hour.
Therefore, the "price tag" of DeepSeek's training cost, compared to OpenAI, directly triggered a panic selloff in the market. Investors are asking themselves: if DeepSeek can build a more powerful LLM for a fraction of OpenAI's training cost, why should we still spend billions of dollars in the US to build AI computing infrastructure? Are these so-called "necessary" compute investments really meaningful? What will happen to the return on investment (ROI) and profitability of AI/HPC data centers?
The chart below visually illustrates the data center revenue per GW for training DeepSeek versus ChatGPT, further highlighting this issue.
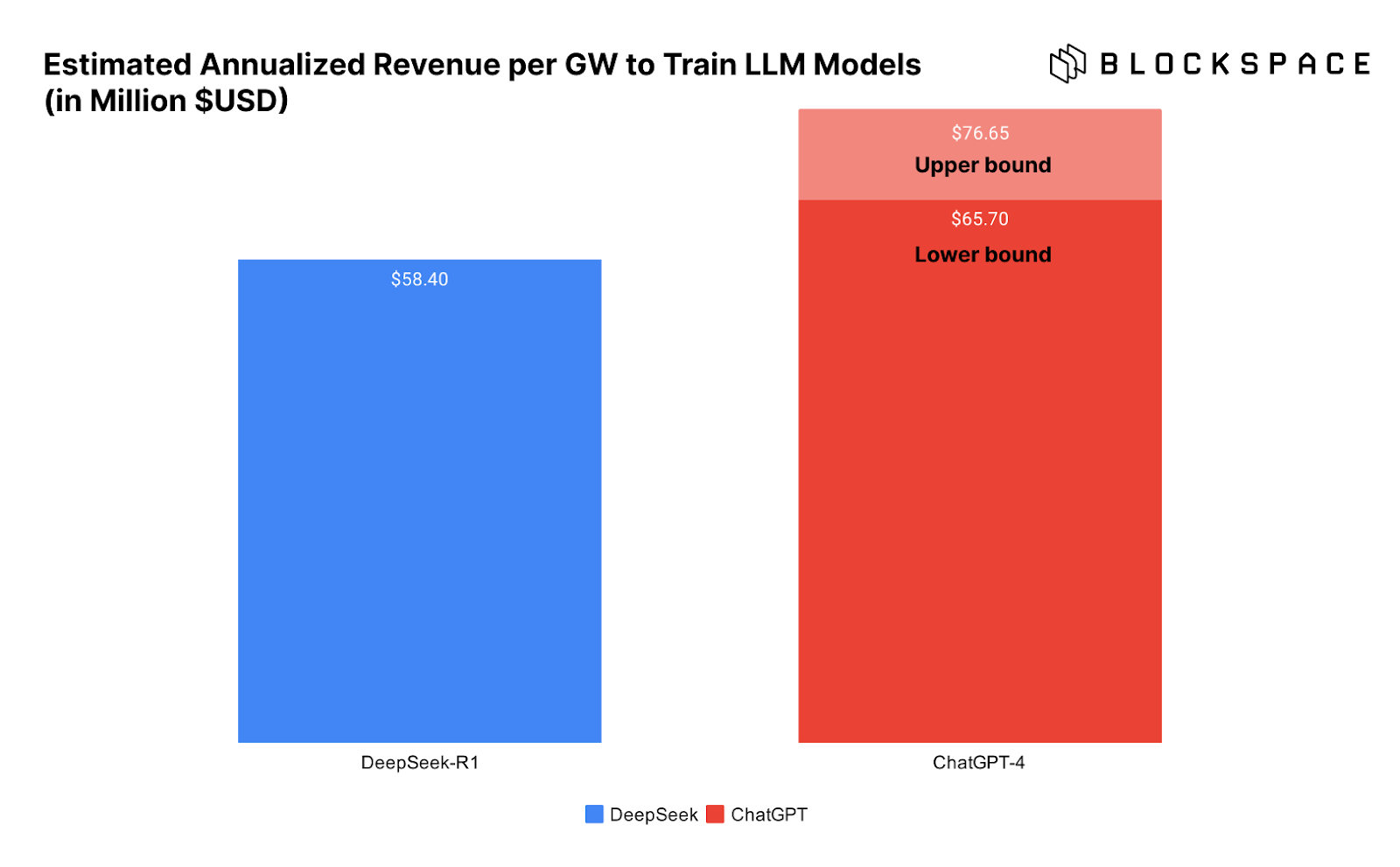
The problem is, we can't be sure that DeepSeek really completed the model training at such a low cost.
Is DeepSeek's Training Cost Really That Low?
However, did DeepSeek really only spend $5.6 million to train the model? Many industry insiders are skeptical, and for good reason.
First, in DeepSeek's technical whitepaper, the team explicitly stated that "the stated training cost only covers the formal training of DeepSeek-V3, and does not include the research and ablation experiment costs on model architecture, algorithms or data in the previous stages." In other words, the $5.6 million is only the final training cost, and there were more financial investments in the model optimization process.
Therefore, Atreides Management CIO Gavin Baker directly stated that "the $5.6 million cost data is highly misleading."
Here is the English translation:"In other words, if a lab has already invested hundreds of millions of dollars in early research and has a larger-scale computing cluster, then it is indeed possible to complete the final training for $5.6 million. But DeepSeek clearly did not just use 2,048 H800 GPUs - their earlier paper mentioned a cluster of 10,000 A100s. Therefore, an equally excellent team starting from scratch, training a model similar to R1 with only 2,000 GPUs, would be impossible to do for just $5.6 million."Furthermore, Baker pointed out that DeepSeek used a technique called "knowledge distillation" to draw experience from ChatGPT to train its own model.
"DeepSeek would likely be unable to complete the training without full open access to GPT-4o and GPT-4o1."





