

This article proposes a novel design for data availability sampling (DAS) and sharded blob mempools, aimed at enhancing scalability while keeping decentralization. The traditional Danksharding strategy assumes a block builder/proposer that creates a block, erasure codes it, and then distributes the complete data to the entire peer-to-peer (P2P) network. This is very demanding in terms of network bandwidth, in particular for small home-stakers where the block builder and proposer are the same node. The proposal in this article overcomes this issue by implementing distributed block building (DBB) with the help of two new ideas: i) Sharded Blob Mempools, and ii) partial column dissemination.
The remainder of this article is organized as follows. First, the underlying assumptions that serve as the foundation for this new design are elucidated. Then, the current DAS and blob mempool designs are presented. Finally, the proposed design and its attendant benefits are articulated.
Assumptions
Here are the main assumptions we work with in this work.
Network Size: The current network size for Ethereum is estimated to be in the order of 10,000 nodes. For this article, we assume the network size will remain between 5,000 and 50,000 nodes, with the understanding that this may change in the years to come.
Block Structure: We assume that all data blobs are composed of 512-byte elements, referred to as “cells,” which are then grouped and extended using erasure coding (Reed Solomon) to create a two-dimensional matrix.
Slot Throughput: Our target throughput is 256 blobs of 128KB each, totaling 32 MB per slot before extension using erasure coding. Thus, the size is 128MB after 2D erasure coding extension.
Data Dissemination: Gossipsub is used to disseminate data at the consensus layer (CL) across multiple channels within the P2P network. We assume Gossipsub can scale to a thousand topics and beyond.
Old Design for DAS and Mempools
Slot Cycle
The whole slot cycle of a block and its blobs can be described in the following four steps.
1. Mempool
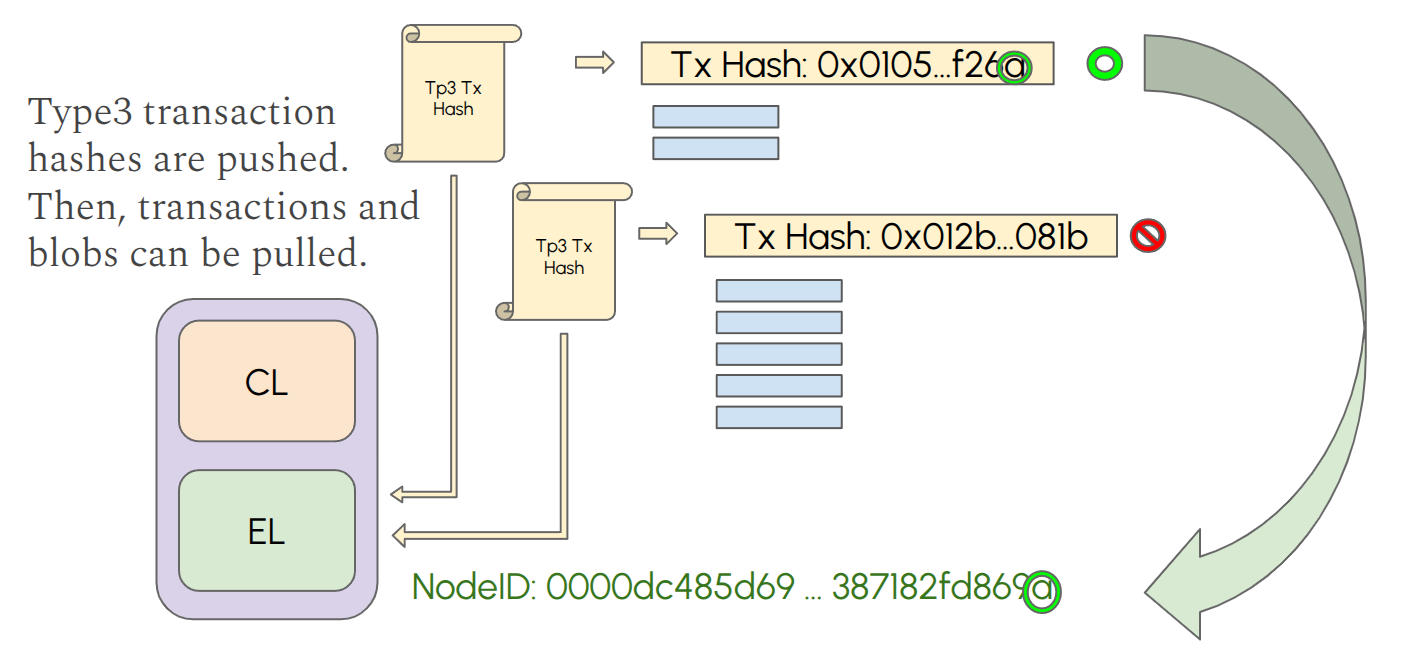
In the Ethereum network, blobs are submitted through a type 3 (0x03) transaction. The transaction can contain one or multiple blobs, up to nine since Pectra. Type 3 transactions are gossiped over the devP2P network. Which means, first the hash of the transaction is pushed to all peers, and then the nodes can decide to pull the transaction and the associated blob data, which is transferred in a BlobTxSidecar. Nodes are not required to download type3 transactions or the blob data if they don’t desire it. Validator nodes that want to build and propose a block should monitor the network for transactions, including type3, and should download all blobs into their mempool. Blob data enters the execution layer (EL) blob mempool, where it waits for inclusion into a block. When the node is selected to propose a block, it will include some of the blobs from its mempool, given that their availability is already verified. Any node can opt to download all blob data for other purposes (e.g., monitoring, research).
2. Building
A block is composed of two main parts: the execution payload and the blob data. The execution payload does not contain the blob data, it only references blobs through type3 transactions. The block builder/proposer selects which blobs to include in the block and in which order. At full scale, it selects up to 256 blobs (128KB each) per slot, resulting in a total of ~32MB of blob data before erasure coding. The block builder extends this data horizontally and vertically through Reed-Solomon encoding, resulting in a 128MB block.
3. Dissemination
The block builder/proposer broadcasts the execution payload to the network for validation and disseminates entire rows and columns through Gossipsub channels. CL nodes only custody (i.e., store) a fraction of all the rows and columns in the block. The number of rows and column to have custody of is decided by each node, but every node has to custody a minimum number of rows and columns. Some nodes can decide to custody all rows and columns, making them super-nodes. CL nodes receive the execution payload, and the entire rows and columns they have custody of through Gossipsub. CL nodes inform other nodes of their custody size in their Ethereum Name Record (ENS). Rows and columns are deterministically derived from the node ID, so that any node can know which rows and columns its peers have custody of.
4. Sampling
CL nodes collectively ensure that all blobs are retrievable without needing every node to store the full block (128MB). Since blobs are extended using erasure coding, even partial blob data allows full reconstruction if enough data is available. CL nodes perform randomized sampling to verify data availability. Every node chooses a number of random cells to sample from its peers. It knows which peers custody which columns/cells, so it can request from them. Alternatively, it can send the request to multiple peers and let any node respond.
Shortcomings of this design
- Validator nodes that want to build/propose blocks have to download all blobs into their mempool.
- The block builder/proposer needs to disseminate (i.e., upload) all the erasure-coded blob data (128MB) when producing a block.
- Blobs are propagated over both the EL and the CL (as rows), leading to redundancy and bandwidth waste.
- Entire rows and columns are disseminated over the network
New Design
Ideas and Rationale
The main objective of this new design is threefold:
- to decrease the amount of data that needs to be downloaded in the blob mempool by the EL nodes,
- to eliminate network redundancies existing between the EL and the CL
- to decrease the amount of data that needs to be uploaded for custody by the CL nodes.
In this section, we present the new concepts that are introduced in this new design.
Horizontally Sharded Blob Mempool
Downloading tens of MBs of blob data every few seconds can put a strain on home-stakers with limited Internet bandwidth. Therefore, we propose a horizontally sharded mempool design so that EL nodes only need to download part of the blobs. The main idea is to shard the nodes based on their node ID and the hash of the type 3 transaction of the blobs they will store: A node should download a type 3 transaction and its related blobs, if and only if the last 4 bits of the hash of the type 3 transaction match the last 4 bits of its node ID. This creates 16 different shards where all type 3 transactions and blobs are disjoint. The same blobs that the EL node downloads into its mempool are the same rows that the CL node will have to custody, so there is no need to download rows over the CL network; they can be acquired through getBlobs from the EL to the CL. This means that for each slot, a node will custody different rows depending on the hashes of the type 3 transactions. Still, it should be fairly simple to calculate which row IDs the peers custody for a given slot, based on the node ID of the peer and the execution payload of the slot. For this example, we used the 4 bits (16 shards), but it does not need to be 4; it could be any number of bits B that shards the 256 blobs we want to have per block. This reduces network bandwidth while simultaneously accelerating data dissemination in the CL layer after the block has been created.
Several points need to be highlighted. Because row custody is based on type 3 transaction hash, the number of blobs/rows a node has to store is not the same from one slot to the next, because it depends on the hashes and the number of blobs per transaction. However, on average, all nodes store statistically the same amount of data. Conversely, for a given slot, not all nodes store the same number of rows. Nonetheless, all blobs are equally distributed among the nodes and robustly replicated. This strategy avoids EL and CL redundancies by eliminating blob/row dissemination at the CL. Another strategy that could be used is validator custody: the number of blobs/rows to store could be directly proportional to the number of validators in the node. For example, the minimum requirement for nodes could be to match the last B bits of the node ID, while for nodes with validators, it could be to match the last B-1 bits. Nodes with more validators are likely to propose blocks more often; therefore, having more blobs in their blob mempool helps them build blocks faster. Also, economically, nodes with multiple validators are likely to have the hardware and network resources to custody more blobs/rows.
Partial Column Dissemination
Columns are different from blobs in that they are only known after the block has been built. Therefore, columns can only be disseminated, even partially, after the block builder/proposer has decided which blobs to include and in which order. In this proposal, CL nodes have a number of columns to custody, and the exact index of the columns is decided deterministically from the node ID, in the same way as in the previous design. These column indices are maintained constant throughout the node’s lifetime. This means, **in opposition to rows, nodes always store the same number of columns at every slot, and always the same ones. This dissonance between rows and columns is crucial for optimizing network bandwidth utilization. At the same time, it enables robust data custody and rapid sampling.
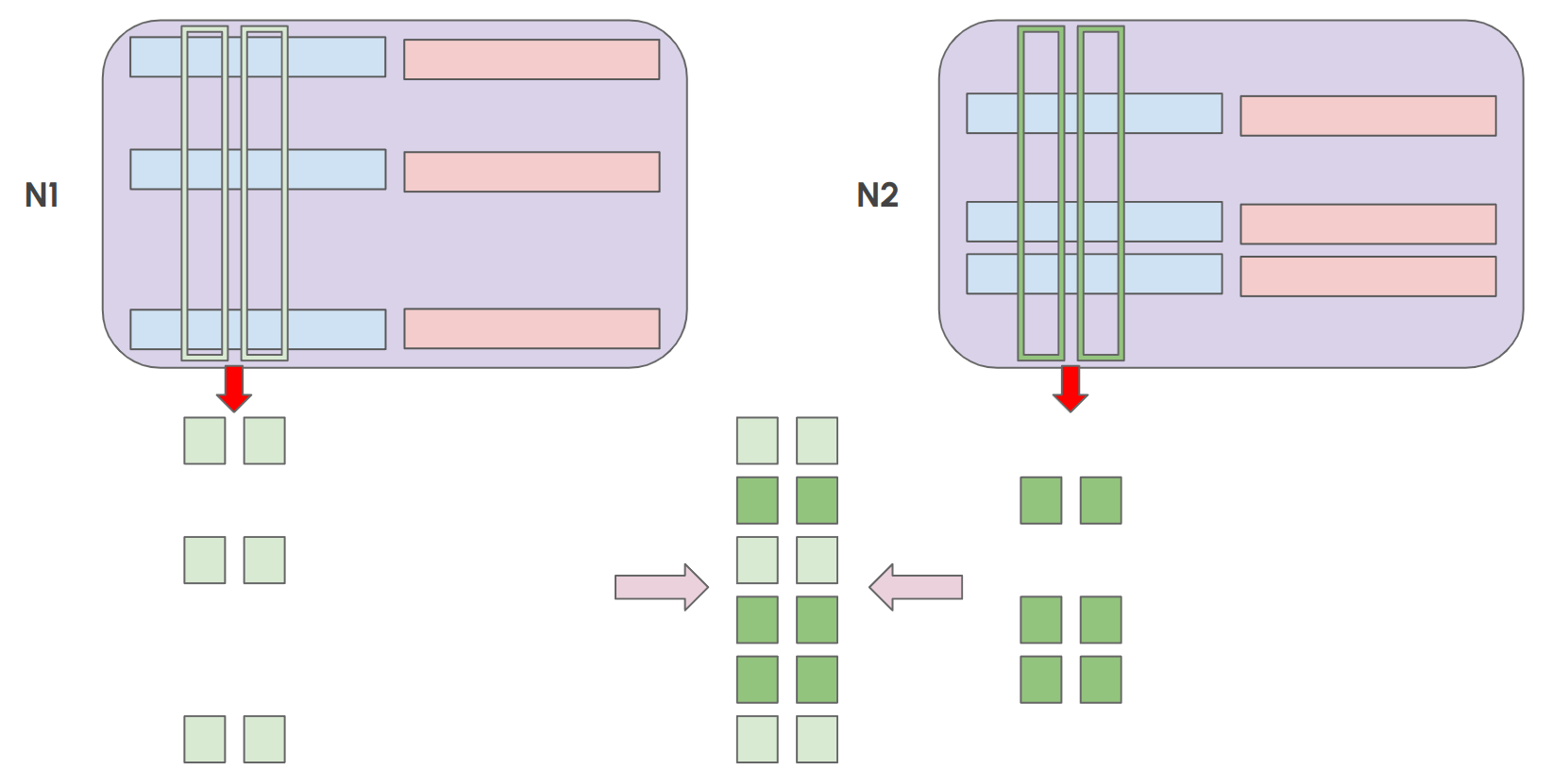
Partial column transfers, in opposition to entire column transfers, are a critical part of this new design, since with horizontally sharded mempools, most nodes will not be able to disseminate entire columns when they receive the execution payload. Therefore, partial column transfers are necessary to disseminate partial data and speed up block diffusion. For instance, if the blob mempool were divided into 16 shards, then to obtain a full column, a node would need to receive 16 partial column messages over the gossipsub topic of that column. By disseminating partial columns from every node as soon as they receive the execution payload, the network does not need to rely on the upload speed of the block builder/proposer to obtain their respective columns. This is particularly important when the block proposer is a home-staker with limited upload bandwidth. In addition, even if all EL nodes had all the blobs in their mempool and shared the full columns to avoid the block proposer bottleneck, they would still be uploading entire columns. In contrast, this design allows each node to send only 1/16 of a column, thereby reducing bandwidth consumption.
New Design Slot Cycle
1. Mempool
The main difference between this design and the existing one is the introduction of a sharded mempool. In this design, nodes download only a certain number of type 3 transactions and related blobs sidecars (i.e., the blob data). The blobs that each node has to custody is calculated from the node ID in a deterministic way, such that every node can know which blobs to download for itself, but also which blobs its peers have custody of. There is a minimum number of type 3 transactions that every node should download and store in its blob mempool. Nodes with validators could custody more blobs in their blob mempool, similar to validator custody. Nodes can opt to download every single blob into their blob mempool, either because they have many validators or because they need it for their tasks (e.g., block builders, rollups, explorers).
2. Building
The objective is to introduce 256 blobs of 128 KB each per slot, totaling 32 MB of blob data, before erasure coding. With this new design, the block builder/proposer has a limited (i.e., sharded) list of type 3 transactions to append to its block. It could decide only to append blobs from its restricted list. However, there is another strategy. Since block proposers are known in advance, a node that has to propose a block in the next epoch, can temporarily change the behavior of its blob mempool, to start downloading all type 3 transactions and blobs until the moment the block is proposed, when they can go back to the standard blob mempool behavior.
3. Dissemination
The first thing that the block builder/proposer should disseminate is the execution payload, which includes the list of type 3 transactions and blobs attached to the block.
CL nodes need to custody (i.e., store) a number of rows and columns from the EC-extended block. In this design, we propose that the rows the CL has to custody, should be the same blobs that the EL should download into their mempool. By doing so, we are sure that, regardless of the blobs included in the block, every CL node following the protocol should not need to receive any horizontal row over the network, as they already have it in their blob mempool. Instead, they can extend it horizontally through erasure coding and transfer it from the EL blob mempool to the CL custody storage. In this context, no node, not even the block builder, should push horizontal rows through the CL network, as there is no need for it because horizontal dissemination occurs at the EL. If, for some reason (e.g., network or hardware failures), a node does not have the blobs it should have in its blob mempool, it can request them from its peers through pulling.
Regarding column dissemination, when a CL node receives the execution payload of the block, it knows which blobs are to be included in the block. Since the node has some of the rows of the block, it also has some cells of the columns the node is responsible for, but not all. Thus, instead of sending entire columns (unless it is a supernode), nodes disseminate partial columns over Gossipsub topics. This should enable fast column retrieval from all peers in the column topic. Once a node has received all the cells from the non-extended column, it extends the column vertically with erasure coding. At this point, all nodes in the network should have their corresponding rows and columns assigned to custody.
4. Sampling
No significant changes in sampling in this new design. Everything happens the same way as in the previous design.
Some Numbers
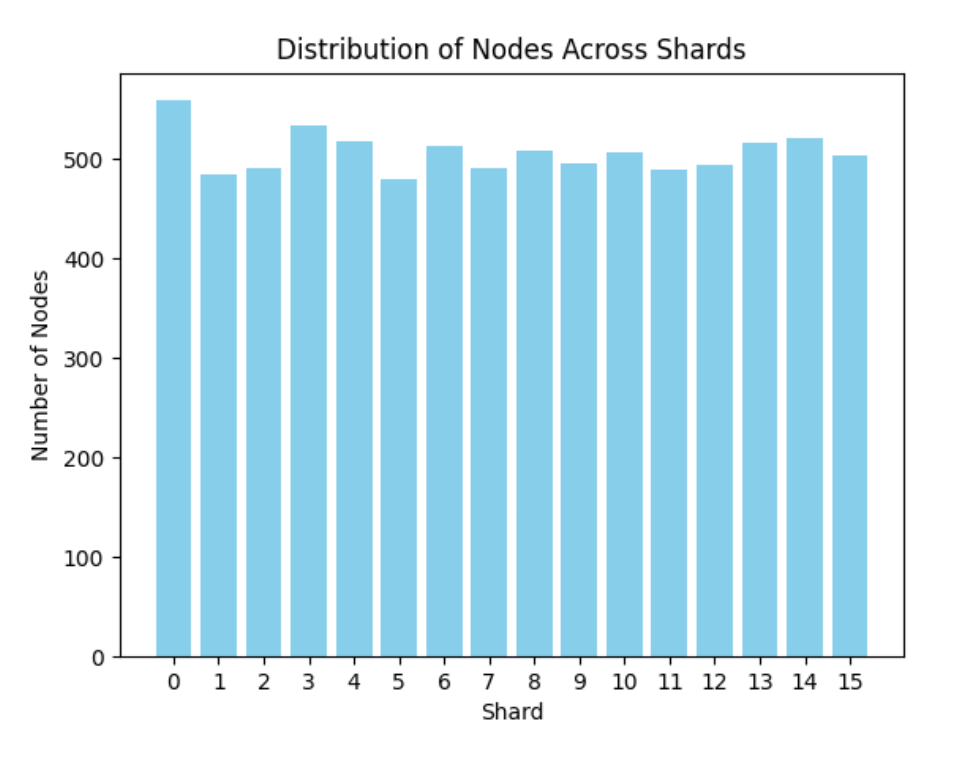
Let’s assume that at any given time, there are about a thousand type 3 transactions from which block builders can choose which ones to introduce in their next block. This makes a blob mempool of roughly 128MB for block builders that want to have all the blobs in their blob mempool. If we assume nodes without validators have custody of blobs that end with the same 4 bits as their node ID, then they hold 1/16 of the blobs. That is 64 blobs (~8MB) out of 1024 on average. Assuming a network with 8,000 nodes and homogeneously distributed node IDs, every blob would be stored across approximately 500 nodes, providing sufficient redundancy and robustness. Thanks to our crawler, we took the current list of EL nodes in the network today, and we sharded them following this design. The figure above shows the number of nodes present in each shard.
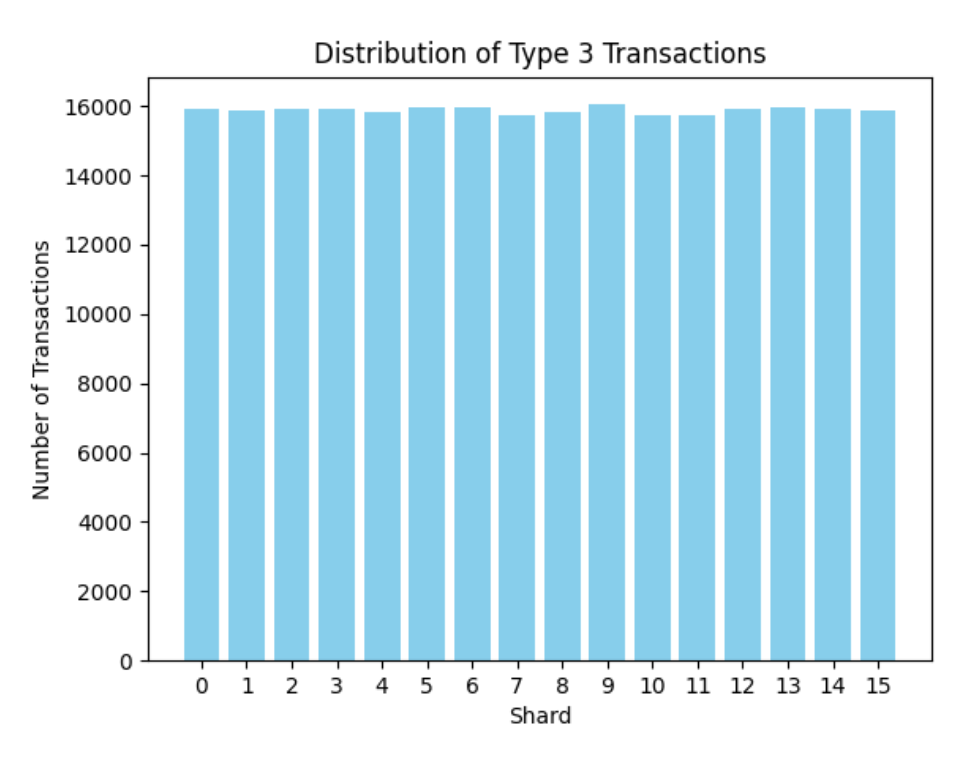
We also analyzed all type 3 transactions from Pectra (May 22nd) to June 3rd (6107 epochs) and plotted them according to their respective shards to check how homogeneously distributed they are. There were a total of 254,097 Type 3 transactions distributed across 16 shards, as shown below.
Similarly, we verified that the 707,923 blobs are also homogeneously distributed across shards.
This does not include multi-validator nodes and super-nodes.
Implementing this New Design
To implement the horizontally sharded blob mempool design presented in this article, EL nodes only need to do one extra check, verify matching hashes, before pulling the type 3 transaction.
For column dissemination, we need to implement partial column transfers, to allow the dissemination of partial columns. This could be as simple as sending a shorter (1/16) column together with the list of the cell’s positions in the column.
Discussion
Several other strategies could complement this proposal:
We could add a blob mempool ticket for introducing a blob into the blob mempool. The ticket can be obtained through an auction. The objective of the blob mempool tickets is to limit the number of blobs that are injected into the mempool, thereby protecting against DoS attacks. However, in this design, the blob mempool is sharded horizontally, so there is not much need for blob mempool tickets.
The block builder/proposer can disseminate all data (rows and columns) on a “best effort” approach. While most data columns will arrive from other peers through partial dissemination, the columns coming from the block builder could be used as a backup strategy.
Nodes should use IDONTWANT messages to reduce bandwidth upon cell reception. Please note that partial dissemination will always disseminate the exact same partial message, because the shards are disjoint and deterministic. Thus, IDONTWANT messages will still work in the context of partial dissemination.
Since column dissemination starts from all nodes simultaneously, we can implement push-pull phase transition strategies while minimizing anonymity concerns.
Acknowledgments
This research was done by the Codex team. We want to thank @dankrad and other DAS researchers for their feedback and contributions.





