

This study was done by @cortze and @yiannisbot from the ProbeLab team (probelab.io), with the feedback of the EF and the PeerDAS community.
Introduction
As part of Ethereum’s roadmap to improve scalability, blob transactions have been introduced to allow more data to be included in each slot. Thus, the more blobs that can be added, the more data can be supported on-chain, which benefits rollups and other scaling solutions.
Because of this, there is ongoing interest in increasing both the target and maximum number of blobs per block. However, this raises some concerns:
- While institutional stakers may have the hardware and bandwidth to handle more blobs, many home stakers do not. This creates a potential imbalance in validator participation.
- Increasing blob counts could also impact the ability of some nodes to stay in sync, especially during reorgs or recovery events, where nodes need to download large amounts of data from a smaller set of peers.
Currently, we don’t have many ways to measure how well the network could handle these situations, aside from looking at how quickly we can download blocks or blobs from other nodes (check out our post, expanding this idea). This provides some insight, but not enough to fully understand the network’s behaviour under stress recovery.
One possible way to reduce the load on individual validators is through distributed block building. Since the Execution Layer (EL) typically receives many blob transactions before they are included in a block, block builders may be able to reduce initial bandwidth usage by assuming that other nodes’ local mempools already contain the necessary blobs for block validation.
The work in the present post builds on our recent study where we measured the theoretical EL mempool hit-rate for blob sidecars. That analysis showed that in over 75% of cases, the EL already had the necessary blob data before the block proposal. However, that study did not check whether the EL could serve the blobs in time for the engine_getBlobsV1 call from the Consensus Layer (CL).
In this follow-up, we look at the empirical hit-rate of blob sidecars in the EL mempool to better understand how feasible distributed block building is in practice, especially in helping validators with limited bandwidth or resources.
TL;DR
- Monitoring the local
engine_GetBlobsV1calls between the CL and the EL shows a high empirical blob hit-rate at the EL’s mempool:- 76.6% of the total requests were successfully retrieved from the local EL mempool to validate the block in under 100ms.
- The remaining 23.4% of the requests were partially responded to. However, in the majority of these partial responses (98%), only a single blob sidecar was missing from the requested list.
- Current network status shows that redistributing all sidecars over the gossipsub network might generate some redundant traffic, as currently, the majority of blobs are already present at the EL mempool by the time a new block is broadcast.
Methodology
To generate and gather all the required samples to have a consistent view of the EL blob mempool, we developed custom tooling that submits an entry row per engine_GetBlobsV1 req/resp that a CL node did to the EL client.
For that, we developed a new event-stream endpoint at a Prysm fork that would expose not only data about the Engine API requests, but also the responses and timings.
Study details
Details of when and how the data was gathered:
- The collected data belongs to the following dates:
| Dates | Pre-Pectra | Post-Pectra |
|---|---|---|
| from | 2025-05-02 | 2025-05-07 |
| to | 2025-05-07 | 2025-05-11 |
- We used the following client pairs:
- Prysm (
custom-fork) ↔ Nethermind (v1.31.9)
- Prysm (
- We run both clients from an Intel Nuc running from a home setup in Spain.
Analysis
With over 9 days of data, the following plots summarise the network’s status before and after Pectra chain blob target and max parameters:
- Before Pectra:
blob-target=3andblob-max-value=6. - After Pectra:
blob-target=6andblob-max-value=9.
Blobs per slot data
The Ethereum community has shown a strong interest in increasing the blob target and maximum values, as these are directly related to the network’s scalability. Higher blob limits can help rollups and other scaling solutions by allowing more data to be posted on-chain.
However, data from our 9-day study shows that only 52.60% of blocks included blob transactions during that period. This suggests that, while the capacity is there, it is not always being fully used in practice.
These patterns might change over time, especially now that the Pectra upgrade has increased the number of blobs that can fit in a block. The following bar charts compare blob usage before and after the upgrade, showing how the distribution of blob transactions has shifted.
Before Pectra, the summaries show that only 53% of beacon blocks included any blob transaction, and 71.87% of them had all linked blob sidecars available at the local EL client.
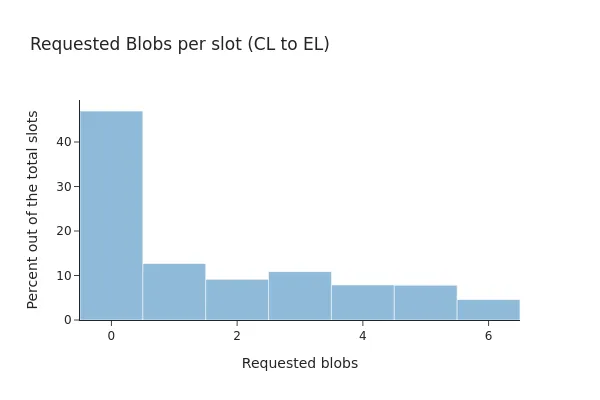
After Pectra, the percentage barely shifted toward 52% of blocks including blob transactions, where 81.82% of the them had all their blobs present at the EL client.
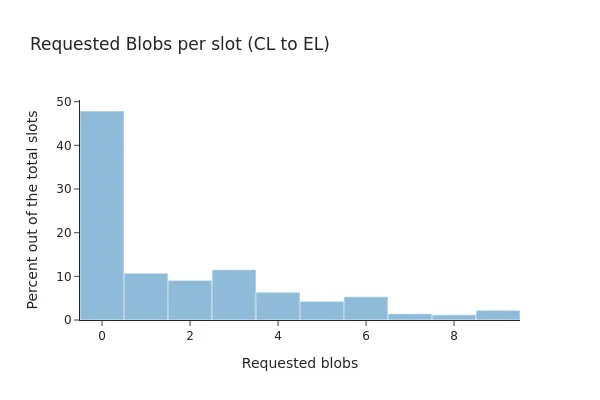
NOTE: despite the network can now make use of higher blobs counts, it looks like the network is still operating under the older parameters (i.e., max of 6 blobs).
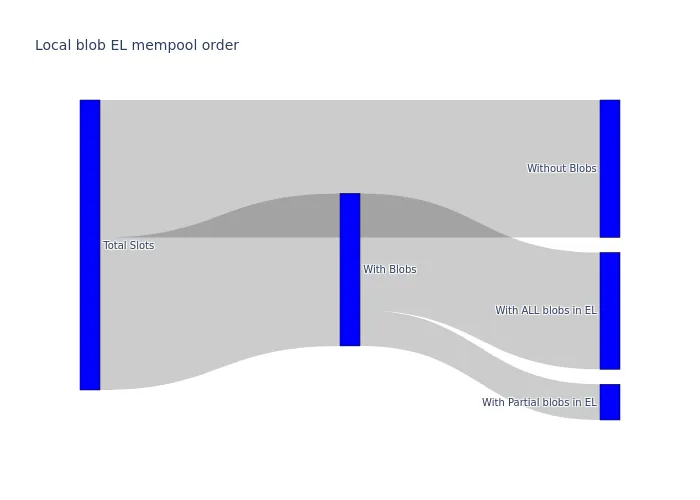
The following Sankey diagram summarises the flow of beacon blocks from the CL’s perspective. The data is aggregated over 9 days, as there were no significant differences between the pre- and post-Pectra upgrade periods. The diagram shows that the number of partial engine_getBlobsV1 requests received by the CL is relatively small compared to the total number of blocks.
Precision of the engine responses
Not all Execution Layer (EL) clients handle engine_getBlobsV1 requests in the same way. Some may only respond if they have all of the requested blobs, while others may return a partial response if they have only some of them. In our setup, Nethermind returns partial responses, which allows us to measure how many of the requested blobs were present in the EL mempool at the time of the request.
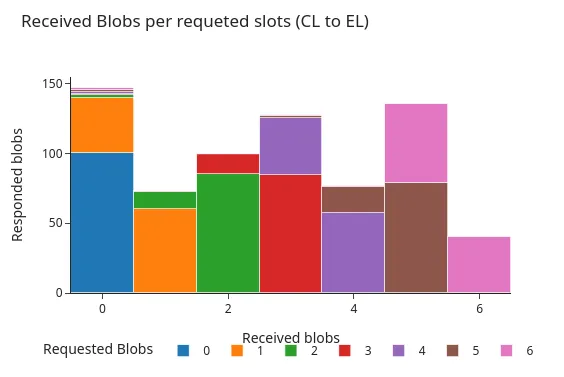
The following figures show the distribution of these responses around the time of the Pectra hardfork. Both charts display histograms of the number of blobs returned by the engine API, grouped by how many blobs were requested. As seen in the figures, the two main response patterns are most common:
- The engine API returns all of the requested blob sidecars.
- The engine API returns all but one of the requested blob sidecars.
Before Pectra:
After Pectra:
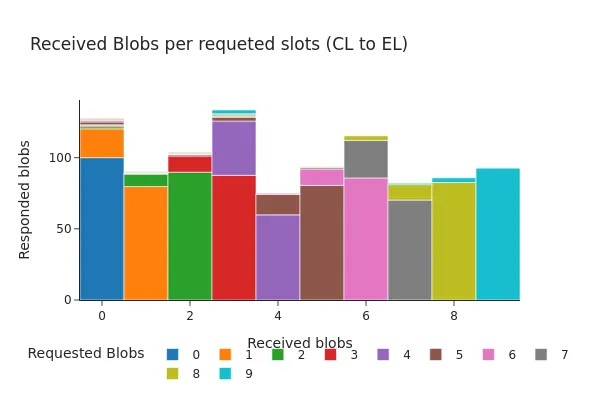
Besides the presence of requests containing up to 9 blobs (enabled by the Pectra upgrade), the two graphs show very similar distributions. In over 98% of cases, either all of the requested blobs were available at the EL at the time of the request, or only a single blob was missing.
While consistently missing just one blob might seem unusual, we believe there are a few plausible explanations for this behaviour:
- The missing blob transaction may have been part of a private mempool, meaning it wasn’t publicly propagated and would only be available through CL gossip.
- The EL may have become aware of the transaction too late, or may not have had enough time to download the full payload before the
engine_getBlobsV1request was made.
To better understand the situation, we cross-referenced the missing blob transactions with Xatu’s mempool database. The results show that 58% of the missing sidecars were never seen in the public mempool at all, which supports the claim that many of these transactions are likely to have been private or recently broadcast.
| Was part of the response? | Was seen at the pub mempool? | number of sidecars |
|---|---|---|
| true | true | 197156 |
| false | true | 4571 |
| false | null | 6392 |
Engine API call and blob reconstruction timings
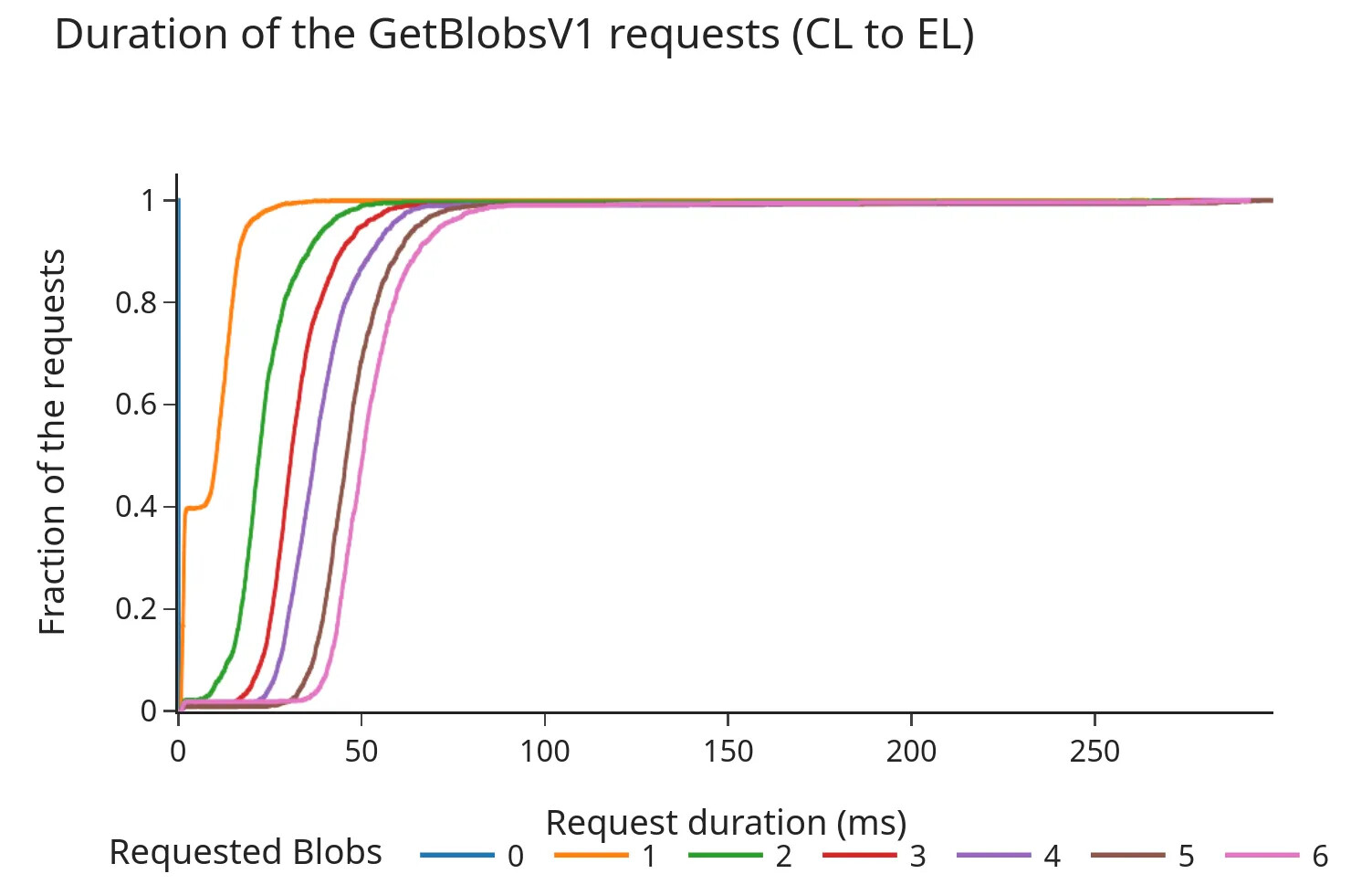
Because the Consensus Layer (CL) cannot wait indefinitely for a response from the Execution Layer (EL), several client teams have discussed whether a timeout should be enforced for engine_getBlobsV1 requests, and if so, what an appropriate value would be.
The following graphs show the Cumulative Distribution Function (CDF) of the request/response duration (in milliseconds) for the engine API.
Before Pectra:
After Pectra:
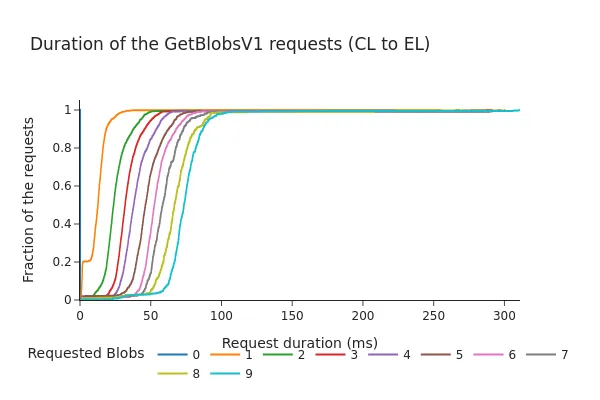
- The CDF shows that 98% of requests are completed in under 100 milliseconds, even after the Pectra fork and the addition of the 3 extra blobs per block.
- The total duration tends to increase almost linearly with the number of blobs requested. Although these times are still within what’s generally considered a “safe margin” (previous discussions suggested a timeout around 200–250 ms), the data indicates that increasing the blob count per slot could lead to longer fetch times from the EL’s blob mempool, especially under higher loads.
Conclusions
This and our previous study were conducted in parallel to @cskiraly ’s one, and, despite the methodology differs, both works converge to the same take-away:
with the current network status and chain’s usage trends, most of the blob sidecars are already available at the EL by the time they get included into a beacon block.
Although this takeaway is generally good news, it shows that the current network is using a significant portion of its resources sending redundant information over the CL sidecar topics, which, in turn, leaves ample space for improvement.
On the one hand, this redundancy ensures that all CL nodes have the required data to process a new block proposal in time, providing resilience successfully. On the other hand, it also becomes its own bottleneck, as all blob sidecars need to be broadcast over the network in a little bit less than 4 seconds (assuming time-games are shortening that window).
Recommendations
With the main intention being to reduce network overhead and node overload, it is worth opening the discussion around PeerDAS and blob sidecar sharing.
With Ethereum’s current PeerDAS proposal, we are only sharding the sidecars at the CL, which is an optimisation at the re-distribution phase of Blobs. However, this only partially solves the problem, as we would still be sending all the blob transactions over the EL mempool, where nodes will indiscreetly download all blobs if their bandwidth allows it.
Even with distributed block building, which can contribute to a faster broadcast of blobs, we would still be sending (at least partially) redundant information.
IDONTWANTmessages help here, but we would still generate many duplicates, which ultimately increase network overhead and node load.
Possible futures
There is a clear and significant benefit from shifting the sharding to the EL’s mempool:
Doing the sharding of sidecars at the EL could simplify the seeding and some pre-computation steps of blobs from the validation network, which could be a new duty for the transaction proposer, i.e., applying erasure coding over the blob-cells and initiating the broadcast.
It would be possible to propose/apply load-balancing properties to the distribution of blobs, which removes the current time restriction of “4s” that the CL has to broadcast the sidecars. Because the blob hasn’t yet been included, we don’t need to enforce any deadlines on its propagation. This further means that slower users can “afford” some extra delay when broadcasting the pieces around.
The EL is currently more efficient at downloading blobs than the CL:
- There is no time restriction when fetching blobs at the EL layer, thus, there is no need to download all blobs we see at once.
- The EL decides when to send a single pull sidecar request, avoiding the duplicates that GossipSubs induces on its average mesh peers → defaults to
D-2duplicates per message (link)
This is largely in line with @cskiraly’s proposal: it may be significantly more efficient to implement sharding at the Execution Layer (EL) rather than at the Consensus Layer (CL).
The idea is still in draft form and explores how we might optimize the use of network resources, as there are still several loose ends to tie up.
As an example of how this could look like, we would like to revisit and share a still-ongoing Blob mempool DHT proposal that the ProbeLab team began drafting a few months ago. It aims to demonstrate how the CL and EL could operate in synchrony to enable more efficient use of network bandwidth and storage (leaving the details on the proposal for a future post). As always, all feedback is welcome.




